Nested Generators, Coroutines, and Python's 'Yield From' Keyword
May 22, 2021
Continuing on with the introduction to coroutines and eventually asynchronous programming in
Python, I'll introduce the motivation and use of Python's yield from keyword.
In my last post, I
introduced generators-as-coroutines in Python. I ended with an example of a not-so-flattering
syntax for retrieving the return value from generators which have raised the StopIteration
exception.
I'm learning all the time, and as I was creating this week's examples, I realized that we are
still (unfortunately) stuck with somewhat unflattering syntax. No matter how you do it, returning
something from a vanilla generator (or a generator-as-coroutine) will raise a
StopIteration exception. Bummer.
However, I can refactor last weeks example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def accumulate():
total = 0
while True:
new_num = yield
if new_num is None:
break
total += new_num
return total
accumulator = accumulate()
accum_inputs = list(range(10))
accum_inputs.insert(0, None)
accum_inputs.append(None)
try:
for ii in accum_inputs:
accumulator.send(ii)
except StopIteration as exception:
print(f'Sum is {exception.value}')
To this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
def accumulate():
''' Same accumulate function as last week
Totals all values sent from the caller. Returns None on each
iteration. Once complete, returns the total accumulated value.
To 'complete' an accumulator, send the value None
:return: Total sum of all accumulated objects
'''
total = 0
while True:
new_num = yield
if new_num is None:
break
total += new_num
return total
def delegator(generator):
''' New 'delegator' function
'Yields from' a specified generator and prints the return
:param: Function (as object) that takes no arguments
:return:
'''
while True:
ret_val = yield from generator()
print(f'Return value is {ret_val}')
# Builds up a list of numbers to add
# [None (primer), 0-9, None (to notify accumulator to complete]
accumulator = delegator(accumulate)
accum_inputs = list(range(10))
accum_inputs.insert(0, None)
accum_inputs.append(None)
for ii in accum_inputs:
accumulator.send(ii)
This second example prints:
Return value is 45
without needing to catch the StopIteration exception and examine the
value attribute. More importantly, it demonstrates the yield from
keyword and nested generators. Let's walk through this step-by-step.
The accumulate function is the same as last week, just with documentation explaining the inputs and outputs.
The delegator function is the new, important functionality to explore here. It is
passed a generator function as an input. It then yields from that generator and
captures it's return value to be printed in the next line.
The yield from keyword can be a difficult concept to grasp. The first thing to
understand is that must take an iterator. Next, visualize that it works similarly to
yield in that it pauses execution and transitions to another context. However,
instead of passing the context up to the caller of the function, it passes the context down to the
iterator parameter. It essentially creates a pipe between the calling code (in this case, the main
script body) and the iterator parameter (the accumulate function). In this example, it allows the
main script body to directly control the accumulate function through the delegator.
It might be easier to understand with a picture:
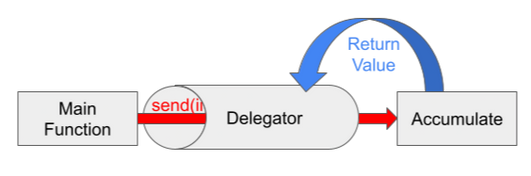
Like the picture shows, the yield from keyword sets up a direct connection from
the main function to accumulate() and does not continue operation until
accumulate() completes its iteration and returns a value. At that time,
yield from generator() evaluates to the return value of accumulate()
(in this case, 45), which is saved to ret_val. Then, context is switched back to
the delegator() function and it continues executing by printing the result of
accumulate().
If this is still as clear as mud, I'll back up a little bit to show an easier example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def yielding_counter():
''' Yields the numbers 0 through 99 using the 'yield' keyword '''
for num in range(100):
yield(num)
def yield_from_counter():
''' Yields the numbers 0 through 99 using 'yield from' '''
yield from range(100)
# Main script body
if __name__ == '__main__':
# Generate numbers 0 through 4 using yielding counter
generator = yielding_counter()
for num in range(5):
print(f'Yielding counter: {next(generator)}')
# Generate numbers 0 through 4 using 'yield from' counter
print()
generator = yield_from_counter()
for num in range(5):
print(f'Yield from counter: {next(generator)}')
In this example, there are two generators: yielding_counter and
yield_from_counter. They both do the same thing. Here's the output:
Yielding counter: 0
Yielding counter: 1
Yielding counter: 2
Yielding counter: 3
Yielding counter: 4
Yield from counter: 0
Yield from counter: 1
Yield from counter: 2
Yield from counter: 3
Yield from counter: 4
When yield from is used with an iterable, it acts just like syntactic sugar for
yielding from that iterable. So when defining nested generators using the yield from
keyword, you can visualize that you are just trying to build the iterable for the
yield from keyword to iterate through.
Let's go one step further.
Here's the previous example written with only the yield_from_counter function.
This time, it is delegating to another generator function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def yield_range_100():
''' Yields the numbers 0 through 99 '''
yield from range(100)
def yield_from_counter():
''' Yields the numbers 0 through 99 using 'yield from' '''
yield from yield_range_100()
# Main script body
if __name__ == '__main__':
# Generate numbers 0 through 4 using 'yield from' counter
print()
generator = yield_from_counter()
for num in range(5):
print(f'Yield from counter: {next(generator)}')
Instead of driving the yield_range_100 generator itself, the main script body
(which is calling next() on yield_from_counter) is driving it.
Plus, it's doing so without needing a ton of infrastructure to handle StopIteration
exceptions and pass next() calls down the chain. Theoretically, you could define
hundreds of nested generators, and all will be driven by the top level calls to
next() and send(). The only limitation is that the innermost
generator has to use the yield keyword or has to yield from an
iterable.
So what's a practical use case for nested generators? There are plenty! Here's an example which I could actually fit in a blog post where a string is searched for in a list of files. Kind of like a simple 'grep' command on Linux:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
def file_reader(file_name):
''' Opens a given file name for reading and yields contents
:param file_name: Path to file
:return: None
'''
with open(file_name, 'r') as file_handle:
for line_no, line_contents in enumerate(file_handle):
# For each call to next(), yield the file name,
# the line number, and the line contents in a tuple
yield file_name, line_no, line_contents
def file_list_reader(files):
''' Iterates through file list and yields their contents
:param files: Containing paths to files to read
:return: None
'''
for file_name in files:
# Delegates to file_reader. Any caller will be yielded
# the file name, line number, and line contents of the
# current line/file since 'yield from' essentially opens
# a pipe from the delegate to the caller.
yield from file_reader(file_name)
def file_search(search_string, files):
''' Searches the contents of the file list for the search_string
Raises EOFError if end of file list is reached without success
:param search_string: To search for
:param files: Containing paths to files to search
:return: Containing file name, line number, contents
'''
# Loop through the file_list_reader generator. Since it is a
# generator, looping can simply be done with the 'in' keyword
# without any knowledge of when the end of a file has been reached.
#
# Note that a tuple with the file name, line number, and line
# contents is returned for each iteration of the loop because
# of the tuple yielded by file_reader.
file_contents = file_list_reader(files)
for file_name, line_no, line_contents in file_contents:
# If the search string is within line_contents, return the
# tuple.
if search_string in line_contents:
return file_name, line_no, line_contents
# If we've made it this far without finding anything, raise an
# error.
raise EOFError(
f'End of files encountered before finding str "{search_string}"')
# Main function
if __name__ == '__main__':
# Define list of files to search and search string
search_string = 'Plumber'
list_of_files = [
'city_names.txt',
'favorite_colors.csv',
'haiku.txt',
'contact_info.dat'
]
# Search for contents
try:
file_name, line_number, line_contents = file_search(
search_string,
list_of_files)
except EOFError as err:
print(err)
else:
# We found our search string! Print out the result
print(f'Found in {file_name} Line {line_number}: "{line_contents}"')
I've added comments to walk you through the code, but here's the gist in three sentences:
-
The
file_searchfunction takes a search string and an iterable of file paths to search -
It delegates to
file_readerandfile_list_readerto provide the file list contents line by line -
If a line contains the search string,
file_searchreturns the line number, contents, and file name
The file_search function can be so simple because of the nested file_reader and
file_list_reader generators. Using the yield and
yield from keywords, allows file_search to be dumb to the fact
that one file ends and the next begins. It simply needs to request the next line of the file list.
Essentially, the file list has been flattened into a single really long file from the view of
file_search.
While this is really handy, this isn't even the reason why I'm so excited about the
yield and yield from keywords. Next week, I'd like to cover how
they can be used for asynchronous programming instead of being limited to confusing, bug riddled
threading. Though Python provides dedicated keywords and libraries for asynchronous programming,
yield and yield from can provide an understanding of the basics.